接上一篇「在 Windows 上安装 Stable Diffusion WebUI」
小试牛刀
在安装完成后打开 Stable Diffusion WebUI
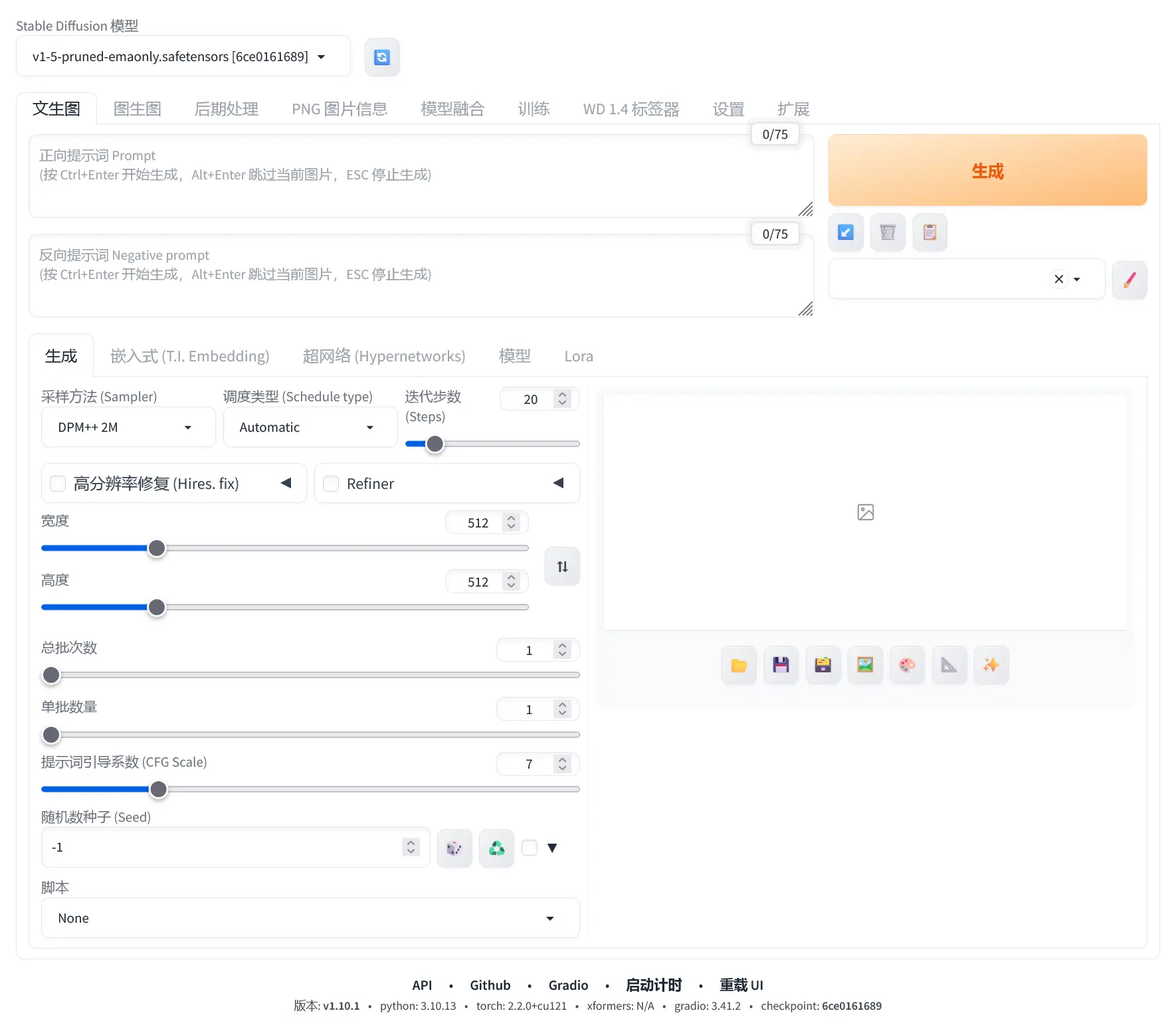
先从熟悉「文生图」开始,我们可以看到页面上方有两个文本输入框,右边还有「生成」及其他几个按钮
这两个文本输入框就是让我们输入「Prompt」,也就是「提示词」的地方。所谓「正向提示词」就是想要什么,而「反向提示词」就是不想要什么。
「提示词」的书写也有一定的格式和建议,这个我们稍后再说。
例如我们现在想画一只猫,你可以在「正向提示词」写上 猫 或者 cat,然后点击右侧的「生成」,然后不出意外你应该就能得到一张猫的图片
在「生成」按钮下方还有几个按钮:
- ↙️:恢复上一次生成的提示词和参数设置;
- 🗑️:清空正向和反向提示词;
- 📋:添加从 🖌️ 预设的正向和反向提示词(例如说你有一套特别好用的关于画猫的正反向提示词,就可以添加到 🖌️ 然后从选项卡里选中,就不用每次输入);
Prompt
接触 Stable Diffusion WebUI 和使用其他生成式 AI 产品类似,首先都要了解一个名为「Prompt」的概念,在中文里「Prompt」通常也被称为「提示词」,用来描述和指导模型生成图像,通俗来讲就是告诉「AI」我们想要画的是什么,如之前输入的 cat 就是 Prompt。
提示词的书写建议
- 使用英文
在文章开头使用了猫的英文
cat来作为提示词,尽管使用中文猫也是可以正常画出猫的图片的,但 Stable Diffusion 模型训练数据集主要来自英文语料库,对于英文单词、短语和语义有很好的理解和建模能力,而对于中文的理解能力相对较差。 如果英文不是很好怎么办?使用翻译工具,如「DeepL」和「彩云小译」; - 使用词组
一般来说目前更多的是使用英文单词而不是自然语句书写,例如我想画一张阳光下猫咪在草坪上的图片,那么提示词可以这么写:
cat, sunshine, on the lawn - 英文逗号隔开或换行 每个 Prompt 使用英文逗号隔开,有时为了可读性会想要换行,那么在当前行的末尾加上英文逗号再换行即可;
- 尽可能的描述
例如主体的描述,比如这是一个什么品种的猫?猫在做什么?有穿着可爱的小毛衣吗等等;
例如场景的描述,是白天吗?有没有阳光?草坪上有什么?
例如风格的描述,是 3D 还是 2D,是像素风还是漫画风?
例如画质的描述,比如说希望生成的图片是高清的:
High dynamic range, vivid, rich details, clear shadows and highlights, realistic, intense, enhanced contrast, highly detailed; - 权重及符号
尽管每个 Prompt 默认权重为
1,但越靠前的提示词顺序权重越高,对生成结果的影响更显著。因此将重要的提示词写在最前面可以确保它们对最终结果有更大的影响力。 另外有一些符号,如使用括号进行权重控制,() 和 {} 括号用于增加权重,[] 括号用于减少权重。 增加的方法有嵌套和指定数值两种方法:
- 每个括号权重的倍数不同,如 () 括号增加 1.1 倍,{} 括号权重增加 1.05 倍,[] 括号 减少 0.9 倍,那么
(red)表示 red 的权重增加 1.1 倍,并且最多可以嵌套三层括号即(((red)))表示权重增加了1.1 * 1.1 * 1.1= 1.331 倍 - 也可以指定数值,如
(red:1.5)表示 red 权重增加 1.5 倍
提示词网站
除了一些书写建议,想要写好提示词也可以看看别人都是怎么写的:
图片存放路径
每次生成的图片都会保留在本地 SD WebUI 根目录下的 outputs 目录,如文生图功能生成的图片就存放在 outputs 的 txt2img-images 里面:
.
├── __pycache__
├── config_states
├── configs
├── embeddings
├── extensions
├── extensions-builtin
├── html
├── interrogate
├── javascript
├── localizations
├── models
├── modules
├── outputs # 图片输出目录
│ └── txt2img-images # 文生图的图片存放目录
├── repositories
├── scripts
├── test
├── textual_inversion_templates
└── tmp生成参数
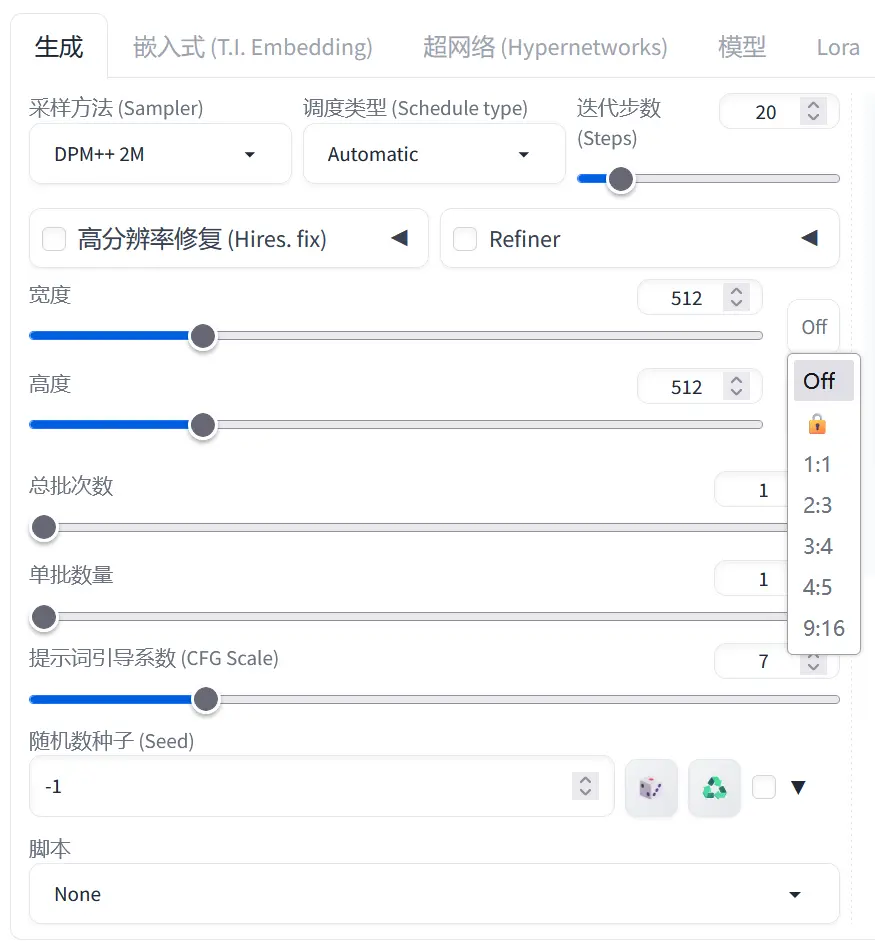
在图片参数设置区域,先暂且忽略掉「采样方法」和「高分辨率修复」
「采样方法」的选项非常非常的多,有的甚至已经过时没有必要使用的,在刚开始的时候我们可以使用默认选项,或是在使用模型(后续文章会提到)时查看模型页面的使用说明,看看有没有推荐会要求使用的「采样方法」即可
宽度与高度
先来看图片的宽高设置,我们可以在此处设置图片的宽高,右侧的 ⇅ 图片可以一键对调宽高设置,此处还推荐一个名为「Aspect Ratio Helper」的插件,可以如上图快速设置如 3:4、9:16 这样的图片比例,也可以选择 🔒 后在拉动宽或高时保持当前尺寸的宽高比,是个很实用的插件
迭代步数
迭代步数(Sampling steps)决定了图像生成过程中的迭代次数。简单来说,迭代步数越多,图像的质量就越好。但是,迭代步数越多,生成图像所需的时间就越长;
一般来说,建议将迭代步数设置为 20 到 50 之间。这个范围可以生成高质量的图像,同时也能保持生成速度。
总批次数和单批数量
总批次数(Batch count)可以一次性生成多批图像,无需重复输入提示词。适合需要大量结果图像的场景。如「总批次数」设置为 5,「单批数量」设置为 1,那么就是每次生成 1 张图片,总共生成 5 次。
单批数量(Batch size)可以在有限的显存资源下,并行利用更多 GPU 计算能力。将数量适当增加能加快单个批次的生成速度,但过高会耗尽资源。如「总批次数」设置为 1,「单批数量」设置为 5,那么就是每次生成5 张图片,总共生成 1 次。
总批次数 * 单批数量 = 生成的图像总数量
提示词引导系数
提示词引导系数(CFG Scale)控制着提示词对图像生成的影响程度。
当数值越高时,生成的图像就越和提示词接近,当数值越低时,生成的图像就越可能缺乏创意或出现不自然的效果。
一般来说,建议将 CFG Scale 设置在 5 到 15 之间。这个范围可以生成与提示词匹配且质量较高的图像。
随机数种子
随机数种子(Seed)用于控制图像生成过程中的随机性,使用相同的种子可以重现相同的结果。
当值为 -1 时随机生成,还可以使用已生成的图片或他人提供的数值,已这个数值生成的图片作为起点,进行自己的修改。
到这里应该已经尝试并掌握一些基本的操作了,但可能很快就会遇到一个问题:「我在网上看到一张画的很棒的图片,并且我用了和作者一样的提示词,为什么画出来的图片还是那么丑?」,可以查看下一篇文章:Stable Diffusion 模型使用入门
浏览「Stable Diffusion 专题」可查看更多内容